資料內(nèi)容:
1. 微調(diào)方法是啥?如何微調(diào)?
fine-tune,也叫全參微調(diào),bert微調(diào)模型一直用的這種方法,全部參數(shù)權(quán)重參與更新以適配領(lǐng)域數(shù)據(jù),效果好。
prompt-tune, 包括p-tuning、lora、prompt-tuning、adaLoRA等delta tuning方法,部分模型參數(shù)參與微調(diào),訓(xùn)練
快,顯存占用少,效果可能跟FT(fine-tune)比會(huì)稍有效果損失,但一般效果能打平。
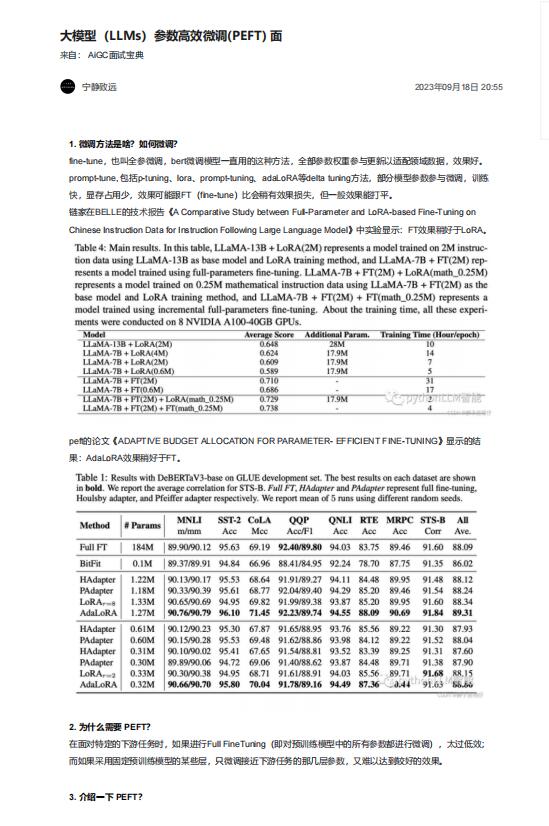
鏈家在BELLE的技術(shù)報(bào)告《A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on
Chinese Instruction Data for Instruction Following Large Language Model》中實(shí)驗(yàn)顯示:FT效果稍好于LoRA。
2. 為什么需要 PEFT?
在面對(duì)特定的下游任務(wù)時(shí),如果進(jìn)行Full FineTuning(即對(duì)預(yù)訓(xùn)練模型中的所有參數(shù)都進(jìn)行微調(diào)),太過(guò)低效;
而如果采用固定預(yù)訓(xùn)練模型的某些層,只微調(diào)接近下游任務(wù)的那幾層參數(shù),又難以達(dá)到較好的效果。
3. 介紹一下 PEFT?
PEFT技術(shù)旨在通過(guò)最小化微調(diào)參數(shù)的數(shù)量和計(jì)算復(fù)雜度,來(lái)提高預(yù)訓(xùn)練模型在新任務(wù)上的性能,從而緩解大型
預(yù)訓(xùn)練模型的訓(xùn)練成本。這樣一來(lái),即使計(jì)算資源受限,也可以利用預(yù)訓(xùn)練模型的知識(shí)來(lái)迅速適應(yīng)新任務(wù),實(shí)現(xiàn)
高效的遷移學(xué)習(xí)。
4. PEFT 有什么優(yōu)點(diǎn)?
PEFT技術(shù)可以在提高模型效果的同時(shí),大大縮短模型訓(xùn)練時(shí)間和計(jì)算成本,讓更多人能夠參與到深度學(xué)習(xí)研究
中來(lái)。除此之外,FEFT可以緩解全量微調(diào)帶來(lái)災(zāi)難性遺忘的問(wèn)題。

